La revolución del procesamiento del lenguaje natural (NLP)
El Natural Language Processing, es un campo de estudio dentro del Deep Learning, cuyo fin es, lograr que las máquinas adquieran la capacidad de procesar y entender el significado del lenguaje humano; una hazaña verdaderamente complicada si tenemos en cuenta algunos factores que nutren nuestro lenguaje, como el orden sintáctico, el tono utilizado, el contexto…factores que influyen en el significado y por tanto en la interpretación de nuestros mensajes. Por este motivo, además de recurrir a la ciencia de datos, para su desarrollo, el NLP implica también el estudio de la lingüística.
A todos nos vienen a la cabeza innumerables ejemplos que tenemos muy presentes en nuestro día a día, como pueden ser los asistentes de voz, los traductores, la redacción inteligentes que autocompletan nuestros correos…Y es que esto del NLP no es cosa de este último año, ni siquiera de esta última década. El afán por el entendimiento entre el hombre y la máquina surge ya por los 60s, con los primeros análisis de texto y de elementos léxicos a través de un ordenador.
Desde entonces, hemos podido comprobar que se han alcanzado hitos especialmente importantes en cuanto a los avances en el procesamiento del lenguaje natural, provocando en cada década cambios significativos dentro de esta disciplina. Avances como la introducción de la valoración de pesos mediante la aplicación estadística, dando lugar a los primeros algoritmos de Inteligencia Artificial; la creación de modelos de interpretación de la voz, la aparición de técnicas de embeddings, los modelos basados en redes neuronales…Unos avances que han sido posibles gracias a la cantidad de datos que a día de hoy somos capaces de generar y a la capacidad de computación actual.
Pero este último año, están siendo especialmente importante para el NLP, y es que, su campo de aplicación es tan amplio, que tanto la comunidad científica como la empresa privada, están sumergidos en una carrera de innovación para este área. Gracias a ello, estamos viviendo una etapa donde los mencionados hitos ya no tardan décadas en llegar, sino que, prácticamente cada mes, surgen modelos que vienen a mejorar al anterior. Un ritmo de crecimiento tan exponencial que tarde o temprano, nos hará replantearnos muchos de los aspectos de nuestro día a día.
Por poneros un ejemplo, hace exactamente un año, en este mismo Blog, estábamos presentando a BERT, el gran avance de Google sobre la actualización de su motor de búsqueda, la cual está basada en una red neuronal de código abierto de aprendizaje profundo relacionado con el procesamiento del lenguaje natural.
Este acontecimiento, ha provocado un gran salto desde la anterior actualización en 2015. A partir de este momento, las máquinas alcanzan a entender el significado de las palabras, teniendo en cuenta el conjunto de toda la oración de la que forma parte. Es decir, que son capaces de extraer el contexto gracias a un sistema bidireccional que evalúa los términos que se sitúan a ambos lados de la palabra a interpretar.
Pero solo tres meses después del lanzamiento de Bert, OpenAI, la compañía sin ánimo de lucro fundada por Elon Musk y Sam Altman, y que apoya la investigación y desarrollo para la democratización de la Inteligencia Artificial, no le bastó con publicar GPT2, que ya igualaba al modelo de Google en número de parámetros utilizados en su entrenamiento, sino que el pasado mes de mayo, decidió publicar en formato Beta, GPT3.
GPT3 es un modelo generador de texto con contenido creíble, que ha sido entrenado con 175.000 millones de parámetros (alrededor de 117 veces más grande que GPT2), y que ha “engullido” prácticamente todo el texto publicado en internet, noticias, blogs, artículos científicos…y que, por supuesto está preparado para seguir aprendiendo, como buen algoritmo de Inteligencia Artificial.
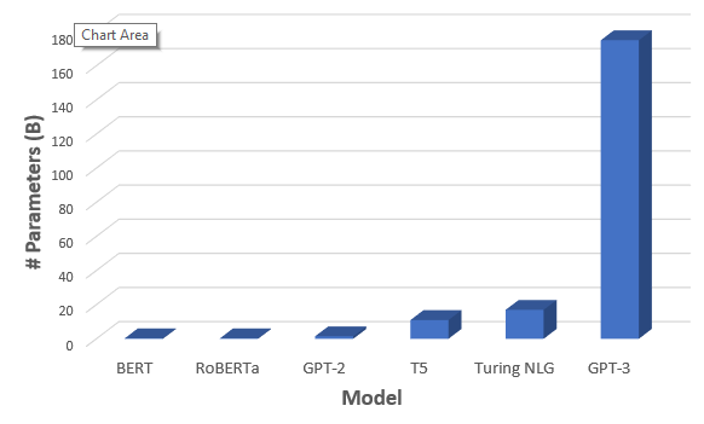
Fuente: www.towardsdatascience.com
Los modelos más innovadores que podemos encontrarnos dentro del NLP, son los denominados Transformers, una arquitectura que pretende cambiar el uso de capas recurrentes de las redes neuronales, por capas denominadas capas de atención.
Tanto Bert, como los modelos de GPT, son modelos basados en estos tipos de arquitectura, pero el funcionamiento de ambos no es exactamente el mismo, ya que para su desarrollo el modelo de Google ha sido entrenado para tareas específicas, como entender y clasificar las intenciones según las búsquedas de los usuarios, mientras que el modelo de GPT, es un modelo llamado general. Esto quiere decir que, el modelo, consigue aprender a través del lenguaje, y logra resolver con éxito multitud de tareas para las que no ha sido entrenado. Esto se produce porque la información con la que se ha nutrido es tan grande y tan diversa en temas y formatos, como todos los posibles en la red. Por este motivo, GPT3 es capaz de realizar tareas como traducir, como resolver preguntas adquiriendo el rol de un Bot; es también capaz de resolver ecuaciones, y lo más espectacular de todo, puede generar contenido original por sí solo y en cualquier formato: ya sea poesía, pentagramas de música, artículos, noticias…incluso logra transcribir el lenguaje natural a scripts de código en varios lenguajes de programación.
Sí, habéis leído bien, es capaz de todo esto, pero ¿Cómo funciona?, el usuario únicamente debe redactar unas pocas palabras previas como modo de introducción, que hagan “programar” el tipo de respuesta que quiera obtener del modelo. El output es un texto que, en ocasiones, ni el propio lector puede distinguir si lo ha escrito una persona o una máquina, son textos verdaderamente realistas, respetando en todo momento la gramática.
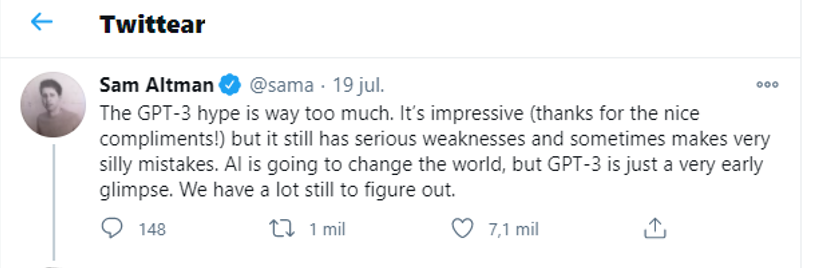
Pero no os asustéis todavía, esto aún se encuentra en pañales. Uno de los propios fundadores, Sam Altman, reconoce que aún es un producto algo inútil sin la supervisión humana, ya que la máquina no detecta la semántica de lo que escribe, no entiende si lo que está diciendo es verdadero o falso, o si tiene coherencia El modelo solo escribe lo que por estadística y probabilidad concluye que es la palabra más idónea a partir de las anteriores. Aun así, reconozcamos que tiene un gran potencial dentro de todos los ámbitos.
Por este motivo, y porque también saben que existe un peligro notable en su aplicación en determinados ámbitos, el pasado junio OpenAI decidió comercializar GPT3 en forma de API, para tener un mayor control, dando acceso solo a unas pocas empresas seleccionadas que quieran aportar más avances, y que traten de mejorar el modelo con casos de uso específicos, entre ellas Microsoft.
Desde Grupo Ideonomía, estamos expectantes, porque sabemos que es solo cuestión de tiempo que empiecen a surgir aplicaciones e interfaces que minimicen las barreras de entrada de la IA, y que mejoren el entendimiento entre hombre-máquina. Permaneced atentos, puede ser que en el próximo post os podamos presentar una de estas herramientas que nos van facilitar el camino para lograr alcanzar la máxima afinidad y ofrecer resultados de mayor calidad en las búsquedas de cada uno de nuestros usuarios.